Introduction
Welcome to the Moknah AI Audio Platform
Overview
Moknah is a comprehensive AI audio platform that converts text into lifelike audio, featuring nuanced intonation, pacing, and emotional awareness. Beyond generation, Moknah empowers your entire workflow with speech-to-text for accurate transcription, automated Video Dubbing, Voice Cloning, and a dedicated Studio for long-form projects.
Whether you are creating content or converting it, our models adapt to your needs across multiple languages and voice styles.
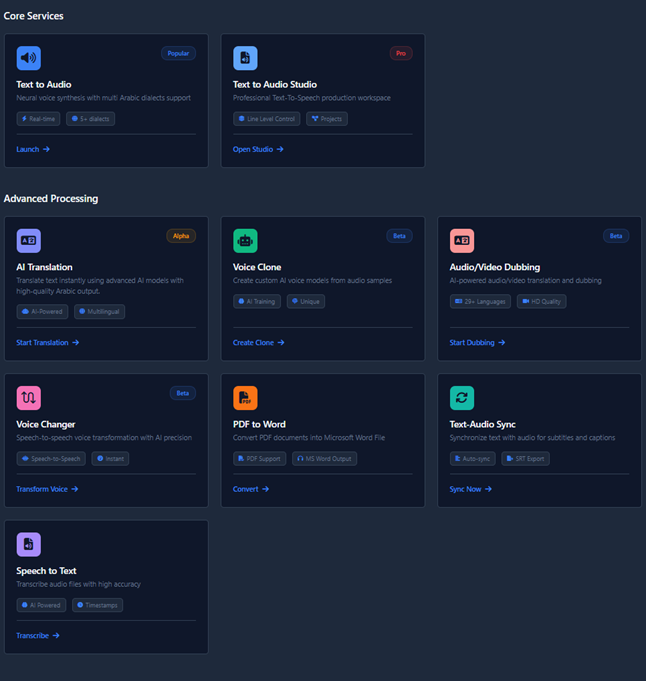
Core Capabilities
- Narrate global media campaigns & ads — Create professional voiceovers for marketing content worldwide
- Produce audiobooks — Multiple languages with complex emotional delivery
- Dubbing — Translate content across languages while preserving original voice characteristics
- Voice Cloning — Create digital replicas of voices with high fidelity
Supported Output Formats
The default response format is mp3 with the following specifications:
| Format | Bitrate | Sample Rate | Available Via |
|---|---|---|---|
MP3 |
128 kbps | 44.1 kHz | Studio & API |
MP3 |
192 kbps | 44.1 kHz | Studio & API |
Ready to Get Started?
Head over to Text to Speech to learn how to generate your first audio.